

Real-Time CDC with Debezium and Kafka for Sharded PostgreSQL Integration
In today’s data-driven world, businesses rely on timely and accurate insights to power analytics, dashboards, and machine learning models. However, integrating data from multiple sources—especially sharded databases like PostgreSQL—into a centralized Data Warehouse (DWH) is no small feat. Sharded databases, designed for scalability, introduce complexity when consolidating data, while real-time requirements demand low-latency solutions that traditional batch ETL processes struggle to deliver.
Enter Change Data Capture (CDC), a game-changer for modern data architectures. Unlike batch ETL, which often involves heavy full-table dumps or inefficient polling, CDC captures only the changes (inserts, updates, deletes) from source databases, enabling real-time data integration with minimal overhead. This approach is particularly powerful for scenarios involving distributed systems, such as sharded PostgreSQL clusters, where data must be unified into a DWH for analytics or reporting.
This article explores how to tackle the challenge of integrating sharded and non-sharded data sources into a DWH, comparing popular approaches like batch ETL, cloud-native solutions, and specialized CDC tools (e.g., Airbyte, PeerDB, Arcion, and StreamSets). We’ll then dive deep into an optimal open-source solution: a pipeline using Debezium (via Kafka Connect), Kafka, and a JDBC Sink to stream data from sharded PostgreSQL to your target DWH. Why this pipeline? It’s cost-effective, scalable, and flexible, making it ideal for teams with DevOps expertise looking to avoid vendor lock-in while achieving true real-time performance.
Understanding the Problem
Consolidating data from diverse sources into a centralized Data Warehouse (DWH) is critical for analytics, reporting, and machine learning—but it’s fraught with challenges, especially when dealing with sharded databases and real-time requirements. Here’s what makes this task complex:
Sharded Databases: Sharding, often implemented in PostgreSQL (e.g., via Citus or custom partitioning), distributes data across multiple nodes for scalability. Each shard functions as an independent database, requiring separate connections and careful coordination to unify data into a DWH, increasing pipeline complexity.
Real-Time Demands: Modern applications—such as operational dashboards or ML pipelines—require fresh data, often within seconds. Delays in data availability can erode business value, making low-latency integration a must.
Scalability Needs: As data volumes grow, pipelines must handle high throughput without bottlenecks, ensuring horizontal scaling across distributed systems.
Schema Evolution: Source databases frequently undergo schema changes (e.g., new tables or columns), which pipelines must accommodate without disruption.
Fault Tolerance: Production environments demand reliability. Data loss, duplication, or pipeline failures can compromise downstream analytics.
These challenges—sharding complexity, low-latency needs, scalability, schema adaptability, and reliability—require a robust integration strategy tailored for distributed, high-performance systems.
Overview of Data Integration Approaches
To consolidate sharded and non-sharded data sources into a Data Warehouse (DWH), several integration methods are available, each balancing latency, cost, complexity, and sharding support. The table below compares popular approaches—including batch ETL, cloud-native solutions, ELT, streaming frameworks, specialized CDC tools, and the Debezium + Kafka pipeline—to help you evaluate their suitability for real-time, scalable data pipelines.
| Tool | Licensing | Sharding Support | Sharding Comment | Schema Evolution | Automation Scale | Use Case |
|---|---|---|---|---|---|---|
| Airbyte | Open-source (free core, paid cloud/enterprise) | Partial | Multiple sources per shard; separate tables, manual merge (dbt/transforms). | Partial (Near real-time polling) | Partial (High-volume limitations) | Good starter; partial sharding via hacks. |
| Debezium + Kafka + Sink | Open-source (free) | Yes | Topic-per-shard to common sink; key-based aggregation, schema consistency via registry. | Partial (Requires DevOps setup) | Partial (Requires DevOps setup) | Max control; ideal for sharded CDC, DevOps needed. |
| Fivetran | Commercial (paid, free trial) | Partial | Multiple connectors; separate schemas/tables, manual DWH merge (dbt/SQL). Sharded imports for large tables. | Yes | Yes | Best UX; costly, merge not internal. |
| PeerDB | Open-source (free core, paid cloud) | Partial | Multi-instance for distributed Postgres (e.g., Yugabyte); merging consumer-side. | Partial (Limited non-Postgres support) | Partial (Postgres-only scaling) | Postgres-only, fast/simple, limited beyond. |
| Arcion | Commercial (paid) | Yes | Multi-source routing/aggregation; configurable rules. | Yes | Yes | Enterprise-ready; not fully open-source. |
| StreamSets | Commercial (paid, free tier available) | Yes | Visual flows for merging multiple sources; CDC pipelines aggregate. | Partial (Complex schema changes) | Yes | No-code; overkill for simple CDC. |
| Meltano | Open-source (free) | Partial | Multiple taps; manual unification or dbt post-load. | Partial (Limited schema flexibility) | Partial (Limited high-volume scaling) | Open-source ELT; SaaS-like to Airbyte. |
This comparison highlights trade-offs in latency, cost, and flexibility. For teams handling sharded PostgreSQL with mixed sources, requiring true real-time capabilities, open-source flexibility, and scalability without vendor costs, the Debezium + Kafka pipeline emerges as optimal—offering robust performance and ecosystem integration while outperforming simpler tools like Airbyte in latency and specialized ones like PeerDB in multi-source support.
Choosing the Optimal Approach: Debezium + Kafka
For teams managing sharded PostgreSQL alongside mixed data sources, the Debezium + Kafka + JDBC Sink pipeline stands out as the optimal choice for several reasons. Its open-source nature eliminates licensing costs, unlike commercial solutions like Fivetran or Arcion, making it budget-friendly for startups and enterprises alike. Unlike Airbyte’s near real-time polling or PeerDB’s Postgres-only focus, Debezium delivers true real-time Change Data Capture (CDC) by leveraging PostgreSQL’s Write-Ahead Log, ensuring minimal latency for analytics and ML pipelines. The pipeline’s scalability, powered by Kafka’s partitioning and fault-tolerant architecture, handles high-volume sharded environments with ease, while its flexibility supports diverse sources (e.g., MySQL, MongoDB) and custom transformations via Kafka Streams. Despite requiring DevOps expertise for setup and management, this trade-off is justified by the control and performance it offers, surpassing simpler tools in latency and specialized ones in versatility.
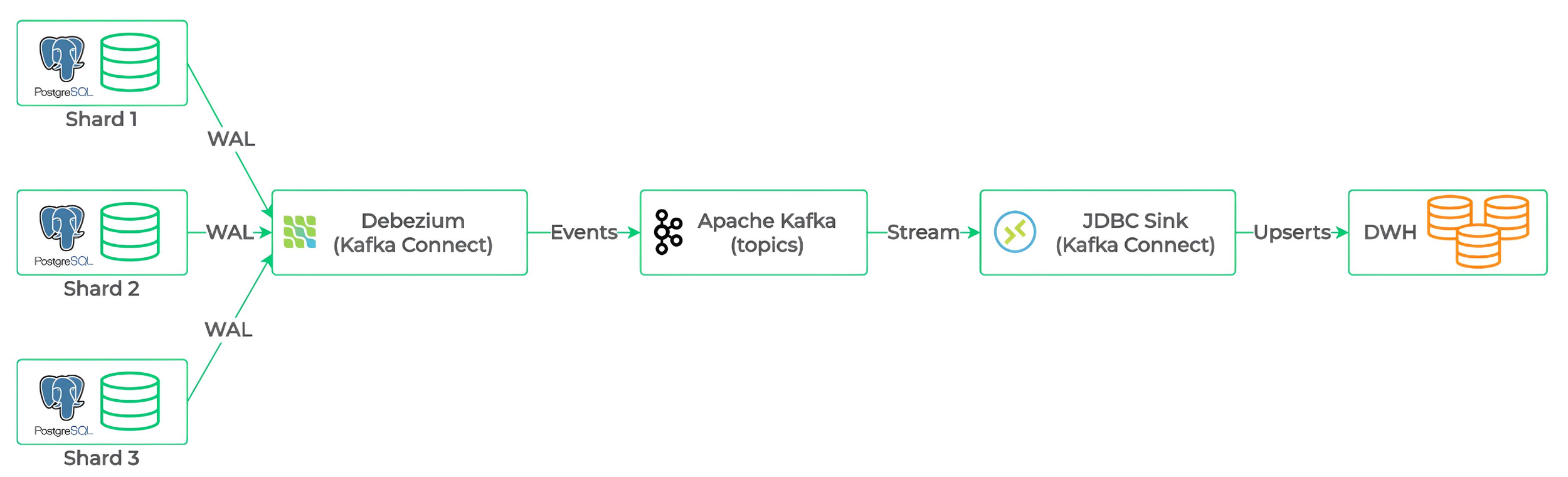
This pipeline streams data from sharded PostgreSQL and other databases to a Data Warehouse (DWH) using a modular, scalable architecture. Its components work together to capture, process, and load changes efficiently:
Kafka Connect: A framework for streaming data between Kafka and external systems, it hosts source and sink connectors to integrate databases with Kafka topics.
Debezium (Kafka Connect): A source connector for Kafka Connect, Debezium captures change events (inserts, updates, deletes) from PostgreSQL’s Write-Ahead Log (WAL). Each shard is treated as a separate database, with a dedicated connector streaming events to Kafka topics.
Kafka: A distributed streaming platform, Kafka buffers and routes events through topics, using partitioning to handle high-volume data from multiple shards and support aggregation into a unified stream.
JDBC Sink (Kafka Connect): A sink connector for Kafka Connect, it consumes events from Kafka topics and writes them to the target DWH (e.g., Snowflake, Redshift, PostgreSQL), enabling upserts for consistent updates and schema alignment.
Flow: Shards → Debezium (Kafka Connect) → Kafka topics → JDBC Sink (Kafka Connect) → DWH.
The pipeline’s design enables seamless integration of sharded data by routing events to Kafka for processing or aggregation before loading. It also supports additional sources (e.g., MySQL, MongoDB) and transformations via Kafka Streams.
Setting Up the Pipeline
Deploying the Debezium + Kafka + JDBC Sink pipeline for sharded PostgreSQL requires a robust setup to stream data to a Data Warehouse (DWH). This guide focuses on Kubernetes with the Strimzi Operator, the most flexible and scalable approach for staging and production in cloud or hybrid environments. For on-premises bare-metal setups, Ansible can be used, but Kubernetes is recommended for its auto-scaling and high availability.
Prerequisites
Kubernetes: Cluster (v1.20+) with resources (e.g., EKS, GKE, on-premises).
PostgreSQL: Version 10+ with logical replication (wal_level = logical).
DWH: JDBC-compatible (e.g., Snowflake, Redshift, PostgreSQL).
Tools: kubectl, Helm, or Strimzi CRDs.
Components
The pipeline includes:
Kafka (brokers): Core streaming platform for event routing and buffering.
Zookeeper or KRaft: Manages Kafka cluster coordination (KRaft for newer, Zookeeper-less setups).
Kafka Connect: Framework running source/sink connectors in separate pods.
Schema Registry: Manages schema evolution for event consistency.
Debezium connectors: Capture PostgreSQL WAL changes within Kafka Connect.
UI (optional): Tools like AKHQ or Redpanda Console for monitoring.
Supports: Auto-scaling, high availability (3+ brokers), external access, StatefulSets with Persistent Volume Claims (PVCs). Ideal for staging/production, cloud, or hybrid infrastructure.
Step-by-Step Setup
Deploy Kafka Cluster with Strimzi:
Install Strimzi Operator: kubectl apply -f https://strimzi.io/install/latest.
Deploy Kafka and Zookeeper/KRaft via Kafka Custom Resource.
Sample kafka.yaml:
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: my-kafka
namespace: kafka
spec:
kafka:
replicas: 3
listeners:
- name: plain
port: 9092
type: internal
storage:
type: persistent-claim
size: 100Gi
zookeeper:
replicas: 3
storage:
type: persistent-claim
size: 100Gi
Apply: kubectl apply -f kafka-connect.yaml.
Set Up Kafka Connect:
Deploy Kafka Connect pods via Strimzi’s KafkaConnect resource, including Debezium and JDBC Sink connectors.
Use 3 replicas for high availability and task distribution.
Sample kafka-connect.yaml:
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnect
metadata:
name: my-connect
namespace: kafka
spec:
replicas: 3
bootstrapServers: my-kafka:9092
config:
group.id: connect-cluster
offset.storage.topic: connect-offsets
config.storage.topic: connect-configs
status.storage.topic: connect-status
externalConfiguration:
volumes:
- name: connector-plugins
configMap:
name: connector-plugins
Apply: kubectl apply -f kafka-connect.yaml.
Configure Debezium Connector:
Deploy a Debezium connector per shard via KafkaConnector.
Use unique database.server.name and slot.name.
Sample debezium-connector.yaml (shard1):
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnector
metadata:
name: shard1-connector
namespace: kafka
labels:
strimzi.io/cluster: my-connect
spec:
class: io.debezium.connector.postgresql.PostgresConnector
config:
database.hostname: shard1-host
database.port: 5432
database.user: user
database.password: pass
database.dbname: shard1
database.server.name: shard1
slot.name: debezium_shard1
publication.name: dbz_publication_shard1
table.include.list: public.my_table
topic.prefix: shard1
Apply for each shard, adjusting identifiers.
Set Up Kafka Topics:
Topics auto-created by Debezium (e.g., shard1.public.my_table) or defined via KafkaTopic for custom partitioning.
Use Single Message Transforms (SMT) to aggregate shard events if needed.
Configure JDBC Sink Connector:
Deploy via KafkaConnector to write to DWH with upserts.
Sample jdbc-sink.yaml:
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnector
metadata:
name: dwh-sink
namespace: kafka
labels:
strimzi.io/cluster: my-connect
spec:
class: io.confluent.connect.jdbc.JdbcSinkConnector
config:
connection.url: jdbc:postgresql://dwh-host:5432/dwh_db
connection.user: dwh_user
connection.password: dwh_pass
topics: shard1.public.my_table,shard2.public.my_table
auto.create: true
insert.mode: upsert
pk.mode: record_key
pk.fields: id
Apply: kubectl apply -f jdbc-sink.yaml. Use Schema Registry for schema consistency.
Monitoring:
Deploy AKHQ or Redpanda Console in Kubernetes for topic/connector monitoring.
Use Prometheus/Grafana for metrics (e.g., lag, WAL growth).
Set slot.drop.on.stop=false to manage PostgreSQL WAL bloat.
Alternative: Bare-Metal with Ansible
For on-premises, use Ansible to install Kafka, Zookeeper, and Kafka Connect on bare-metal servers, configuring connectors via REST APIs. Less suited for dynamic scaling compared to Kubernetes.
Sharding Considerations
Per-Shard Connectors: Unique database.server.name and slot.name per shard.
Aggregation: Route events to a single topic with SMT or Kafka Streams.
Automation: Use Helm/Kubernetes for dynamic shard connectors.
This Kubernetes setup with Strimzi ensures scalable, high-availability streaming from sharded PostgreSQL to a DWH. The next section covers handling sharded databases in detail.
Handling Sharded Databases
Sharded PostgreSQL databases, such as those using Citus or custom partitioning, present unique challenges for data integration due to their distributed nature. Each shard acts as an independent database, requiring tailored configuration to stream changes to a Data Warehouse (DWH). The Debezium + Kafka pipeline addresses these challenges effectively through careful connector setup and event management.
Key Challenges
Independent Shards: Each shard requires its own connection, complicating event capture and aggregation.
Event Consistency: Ensuring events from multiple shards are unified into a coherent dataset in the DWH.
Dynamic Sharding: New shards may be added, requiring automated connector management.
Solutions
Per-Shard Debezium Connectors: Deploy a Debezium connector for each shard within Kafka Connect, using unique identifiers to avoid conflicts. Set database.server.name and slot.name per shard to isolate Write-Ahead Log (WAL) streams. For example, for a shard named shard2:
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnector
metadata:
name: shard2-connector
namespace: kafka
labels:
strimzi.io/cluster: my-connect
spec:
class: io.debezium.connector.postgresql.PostgresConnector
config:
database.hostname: shard2-host
database.dbname: shard2
database.server.name: shard2
slot.name: debezium_shard2
publication.name: dbz_publication_shard2
table.include.list: public.my_table
topic.prefix: shard2
Apply similar configs for each shard, ensuring unique topic prefixes (e.g., shard2.public.my_table).
Event Aggregation: Route events from multiple shard-specific topics (e.g., shard1.public.my_table, shard2.public.my_table) to a single topic for unified DWH loading. Use Kafka Connect’s Single Message Transforms (SMT) to rewrite topic names or merge events. Example SMT for aggregation:
transforms: route transforms.route.type: org.apache.kafka.connect.transforms.RegexRouter transforms.route.regex: shard[0-9]+.public.my_table transforms.route.replacement: public.my_table
Alternatively, use Kafka Streams for complex aggregation logic (e.g., joins across shards).
Automation for Dynamic Sharding: In environments where shards are added dynamically (e.g., auto-scaling Citus clusters), automate connector deployment using Kubernetes tools like Helm or custom operators. A Helm chart can template KafkaConnector resources, updating database.server.name and slot.name based on shard metadata. Example Helm snippet:
{{- range .Values.shards }}
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnector
metadata:
name: {{ .name }}-connector
spec:
class: io.debezium.connector.postgresql.PostgresConnector
config:
database.hostname: {{ .host }}
database.dbname: {{ .name }}
database.server.name: {{ .name }}
slot.name: debezium_{{ .name }}
publication.name: dbz_publication_{{ .name }}
{{- end }}
Proven techniques
Unique Identifiers: Always use distinct database.server.name and slot.name to prevent WAL conflicts across shards.
Topic Management: Monitor topic growth and partition counts to handle high-volume shard events.
Testing: Validate aggregation logic in a staging environment to ensure events merge correctly in the DWH.
This approach ensures seamless streaming from sharded PostgreSQL, unifying data for downstream analytics. The next section explores the pipeline’s pros and cons.
Pitfalls and Best Practices
Running the Debezium + Kafka + JDBC Sink pipeline for sharded PostgreSQL in production can encounter operational challenges. Below are key pitfalls and targeted solutions to ensure reliable streaming to a Data Warehouse (DWH).
Pitfalls
WAL Bloat and Performance: Large transactions or unconsumed events inflate PostgreSQL’s Write-Ahead Log, slowing sources; unbalanced partitions delay processing.
Event Duplication: Kafka’s at-least-once delivery risks duplicates in the DWH during restarts or network issues.
Schema Changes: Evolving schemas (e.g., new columns) can disrupt the pipeline if not synchronized.
Sharding Complexity: Managing connectors for dynamic shards risks configuration errors or topic conflicts.
Security Risks: Unsecured connections expose sensitive data.
Best Practices
Optimize WAL and Performance: Set slot.drop.on.stop=false in Debezium configs; monitor WAL with pg_stat_replication_slots. Use 10+ partitions per shard and 3+ Kafka Connect replicas, tracking lag via Prometheus/Grafana.
Prevent Duplicates: Configure JDBC Sink with insert.mode=upsert and pk.fields for idempotent writes.
Handle Schema Evolution: Use Confluent Schema Registry with Avro for compatibility across shards and DWH.
Simplify Sharding: Automate connector deployment with Helm for dynamic shards, ensuring unique database.server.name and slot.name. Test in staging.
Secure Connections: Enable SSL for Kafka, PostgreSQL, and DWH; use Kafka ACLs for topic access.
These solutions ensure robust streaming from sharded PostgreSQL. The next section concludes with a recap and next steps.
As data landscapes grow more complex, mastering CDC tools like Debezium and Kafka equips engineers to build adaptable pipelines that scale with demand. To get started, experiment with the configurations in a test cluster, incorporating your specific sharding patterns and monitoring tools. For deeper exploration, integrate advanced features like custom transformations or hybrid cloud setups.